> ## Documentation Index
> Fetch the complete documentation index at: https://distillkitplus.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Introduction
# Welcome to DistilKitPlus
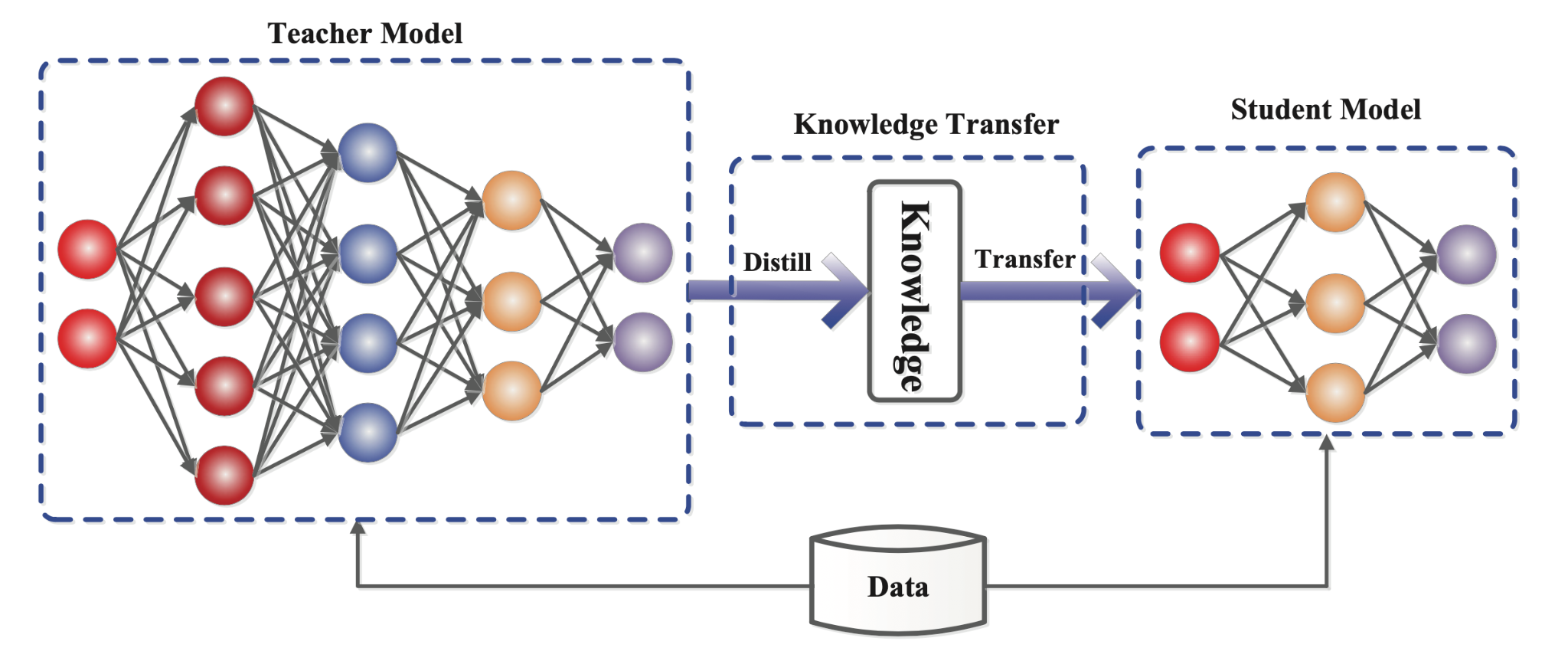
`DistilKitPlus` is an open-source toolkit designed for high-performance knowledge distillation, specifically tailored for Large Language Models (LLMs). It enables you to create smaller, faster, and more efficient models that retain the capabilities of larger teacher models.
Inspired by [`acree-ai/DistillKit`](https://github.com/arcee-ai/DistillKit), this project provides an easy-to-use framework with a particular focus on supporting **offline distillation** (using pre-computed teacher logits) and **Parameter-Efficient Fine-Tuning (PEFT)** methods like LoRA, making it suitable for environments with limited computational resources.
Why DistilKitPlus?
- Lower deployment costs with smaller, quantized models
- Improve inference speed for production applications
- Maintain high-quality outputs with proven distillation techniques
- Fine-tune efficiently with minimal computational resources
## Key Features
* **Logit Distillation**: Supports standard knowledge distillation using logits, primarily for same-architecture teacher/student pairs.
* **Pre-Computed Logits**: Train efficiently by generating teacher logits beforehand, saving memory during the student training phase (See [Generating Teacher Logits](./running-distillation#generating-teacher-logits-optional)).
* **PEFT Integration**: Leverages the `peft` library for efficient fine-tuning techniques like LoRA.
* **Quantization Support**: Load base models in 4-bit precision using `bitsandbytes` for reduced memory footprint and potentially faster execution.
* **Distributed Training**: Integrates with Hugging Face `accelerate` and `deepspeed` for scaling training across multiple GPUs or nodes.
* **Flexible Loss Functions**: Includes various distillation loss options like Forward KL Divergence (`fkl`), Universal Logit Distillation (`uld`), and Multi-Level Optimal Transport (`multi-ot`).
## Getting Started
Ready to distill your own model? Head over to the [Installation](./installation) guide to set up the library and then follow the steps in [Running Distillation](./running-distillation) to run your first distillation job.
## Dive Deeper
Explore the **Essentials** section in the sidebar to understand the core components:
* **[Losses](./essentials/losses)**: Explore the available distillation loss functions.
* **[Configuration](./essentials/configuration)**: Learn how to set up your distillation runs.
* **[Formatters](./essentials/formatters)**: Learn how raw data is prepared for the models.